
Introduction
What is granary?
Granary is a job runner for cloud-based geospatial machine learning. Its goal is to simplify running tasks and to track and serve the results of executions. It puts a REST API between you and AWS Batch to simplify interactions that otherwise involve repeatedly checking AWS SDK documentation. You can see an OpenAPI Spec for Granary here.
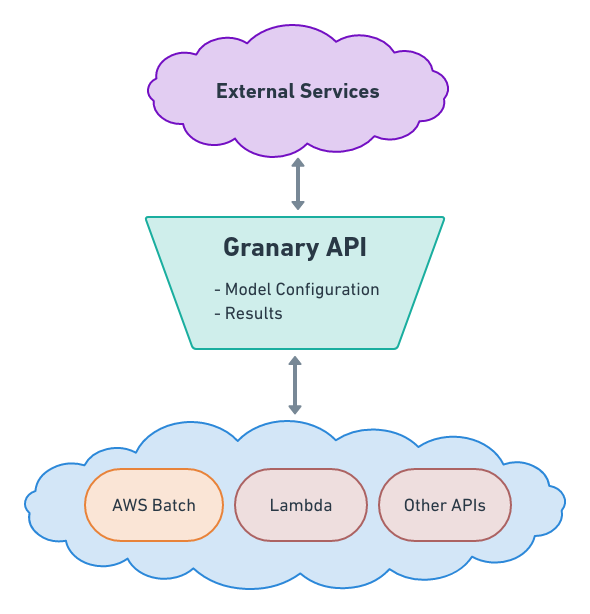
What's a Task?
A task is a bundle of a human-readable name, some AWS Batch configuration,
and an argument validator. Tasks in Granary correspond to containers that
have been configured to run via AWS Batch job definitions. The major difference
between using Granary and hand rolling SubmitJob requests is the Validator.
To create a task, POST JSON like this to /api/tasks:
{
"name" : "A descriptive task name",
"validator" : {
"schema" : {
"$schema" : "http://json-schema.org/draft-07/schema",
"$id" : "http://example.com/example.json",
"type" : "object",
"title" : "The Root Schema",
"description" : "The root schema comprises the entire JSON document.",
"required" : [
"foo"
],
"properties" : {
"foo" : {
"$id" : "#/properties/foo",
"type" : "integer",
"title" : "The Foo Schema",
"description" : "An explanation about the purpose of this instance.",
"default" : 0,
"examples" : [
3
]
}
}
}
},
"jobDefinition" : "perfectAccuracyTask:1",
"jobQueue" : "veryExpensiveOnDemandQueue"
}
If that's successful, here's what the response will look like:
{
"id" : "1d99bab2-1470-46c8-aa00-a8a2ced5c60c",
"name" : "A descriptive task name",
"validator" : {
"schema" : {
"$schema" : "http://json-schema.org/draft-07/schema",
"$id" : "http://example.com/example.json",
"type" : "object",
"title" : "The Root Schema",
"description" : "The root schema comprises the entire JSON document.",
"required" : [
"foo"
],
"properties" : {
"foo" : {
"$id" : "#/properties/foo",
"type" : "integer",
"title" : "The Foo Schema",
"description" : "An explanation about the purpose of this instance.",
"default" : 0,
"examples" : [
3
]
}
}
}
},
"jobDefinition" : "perfectAccuracyTask:1",
"jobQueue" : "veryExpensiveOnDemandQueue"
}
What's a Validator?
A Validator uses JSON Schema Draft 7 to ensure that
when you try to run your job, you have the correct arguments. For example, in the
example above the Validator expects a JSON object with a key foo and some numeric
value. A more realistic (if more verbose) schema for geospatial applications is shown
below, requiring a green band, a red band, and a GeoTIFF location:
{
"definitions": {},
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/root.json",
"type": "object",
"title": "The Root Schema",
"required": [
"greenBand",
"redBand",
"tiffLocation"
],
"properties": {
"greenBand": {
"$id": "#/properties/greenBand",
"type": "integer",
"title": "The Greenband Schema",
"default": 0,
"examples": [
3
]
},
"redBand": {
"$id": "#/properties/redBand",
"type": "integer",
"title": "The Redband Schema",
"default": 0,
"examples": [
2
]
},
"tiffLocation": {
"$id": "#/properties/tiffLocation",
"type": "string",
"title": "The Tifflocation Schema",
"default": "",
"examples": [
"s3://cool-bucket/image.tiff"
],
"format": "uri"
}
}
}
With this JSON schema attached to our task, it's impossible to create task runs with improper or improperly formatted arguments.
Over time, your task's input requirements may change. In that case it makes
sense to make a new task with a different validator. Since writing JSON schema
by hand is tedious, it's helpful to use json-schema.net
to generate schemas from examples, then edit those to match your needs.
What's a Execution?
A Execution is a single run of a task with specific inputs. Executions are
created when you POST a task id and arguments to /api/executions.
{
"taskId" : "1d99bab2-1470-46c8-aa00-a8a2ced5c60c",
"arguments" : {
"foo" : 4
}
}
The task's JSON schema is used to validate the execution's arguments. If validation passes, Granary will insert a record for this execution and submit a job to AWS Batch with the resources configured on the task. If that was successful, you'll receive a response that looks like this:
{
"id" : "78d4345a-5c22-43ec-8a9a-fe354915c3eb",
"taskId" : "1d99bab2-1470-46c8-aa00-a8a2ced5c60c",
"invokedAt" : "2020-03-03T15:16:51.188Z",
"arguments" : {
"foo" : 4
},
"status" : "STARTED",
"statusReason" : null,
"results" : [
],
"webhookId" : "f0ff558a-f989-4648-b606-abcf8b977e6c"
}
The webhookId in the response points to a single-use webhook for updating the execution.
This webhook can be accessed at /api/executions/{executionId}/results/{webhookId} and
accepts two kinds of messages.
If the execution failed, clients should send messages like this:
{
"message" : "everything went wrong"
}
If the execution succeeded, clients should send messages like this:
{
"results" : [
{
"href" : "s3://where/the/results/live.json",
"title" : "Execution Results",
"description" : "results for a very important execution",
"roles" : [
"data"
],
"type" : "application/json"
}
]
}
In the ideal case, the container for running the task in batch will submit results when it
is done or fails. This strategy will not cover cases in which the task cannot perform
error-handling though, for instance, OutOfMemory errors and cases in which a spot
instance gets cycled out from under your running task. Because the space of things that
can go wrong is nearly infinite, Granary itself doesn't provide any facilities for handling
those sorts of errors or for retrying executions. Additionally, if your task has retrying
logic, it's your responsibility to make sure that it doesn't POST to the results webhook
until it has exhausted its retries, since the first POST to the webhook will make it
inaccessible for the rest of time.